






Model-based Demonstrator for Smart and Safe Systems
Hard(ware) working day!
Yesterday I was playing around the Texas Instruments 4.4 real-time kernel. After installing the image it turned out the script copying the contents of the SD card to the eMMC script was broken.
After some poking around, and debugging I found the source of the mystery, and opened an issue with the solution.
https://github.com/RobertCNelson/boot-scripts/issues/20
Just after some hour, RobertCNelson, the maintainer of everything in the BeagleBone Black project issued a fix. That was fast!

Most of us get in elevators, ride trains and board airplanes without thinking about the danger. It became widespread to trust technology – or at least those parts that have been surrounding us ever since we were born. We were taught that these devices are safe. Nothing operates perfectly of course, but these devices manage to keep the severity of failures to a minimum somehow. However, in the IT world, having a few errors in projects with millions of lines of code is more than common. So how is it that these systems can still operate safely?
Safety critical development
In safety-critical and also mixed-criticality systems – such as ours – it is very important to ensure the correctness not only at design time, but also at the working of the system. Traditional verification, as it was introduced in former post, can find design problems early in the design process. However, it would be a great idea to use the formally verified specification also at runtime to check if the runs of the system conforms to the specification.
There are many problems which cannot be handled by traditional design time verification. We generate the code from the design models. However, there is no assurance, that the code generator is correct. The second problem is that we can not verify our hardware. Problems caused by the hardware cannot be taken into account in the verification of the distributed logic. In addition, there can be transient or permanent errors in the components caused by short-circuit or many other kinds of events. Communication problems might result the loss of messages in the system, or errors in the network components might cause huge problems in the system.
Actually, in our small system we have faced many of the aforementioned problems, especially network delays caused serious problems and “accidents”.
Runtime verification
The output of running systems can be validated by external components checking conformance. For complex systems, only safety critical parts are monitored to be cost efficient. Our approach is to generate small monitors receiving the same inputs as the running component and verifies if the output is correct. Erroneous behavior can usually be detected by much smaller components. Imagine for example an airplane that with a safety criteria that it’s acceleration can’t go above 30m/s^2. The components that control the exact power of the engines can be complex, and done by many different parts of the system. Any error anywhere in the chain could lead to faulty behavior. A single component at the end can monitor the result, and if the final value would result in an acceleration higher than 30m/s^2, can signal an error. Such monitors are simple and efficient means to check certain properties.
Workflow
Monitoring components have a much lower complexity than the system itself, so they can easily be generated from models and we can trust in their correctness in a higher confidence. One of the most widely known modeling methods in the engineering world is statechart based modeling, so our approach is based on engineers creating statechart models, which then can be used to generate monitoring components with minimal non-generated code (glue code required to connect signals in the statecharts to the actual systems that they monitor).
Statechart based monitors
There are many flavors of statechart languages from low level ones which resemble state machines, to complex ones like UML statecharts. Our goal was to develop an intuitive and highly expressive statechart language with features like error state annotation to make monitor generation easy. A simple statechart can be described as following:
The described system simply switches between an odd and an even state on every tick signal. The features of the UML statecharts are fully available (entry and exit actions, state hierarchy, etc) with a few extensions, like parametrized handling of certain situation. A system specification can hold multiple statechart definitions which can communicate via shared signals.
Monitor generation from statecharts
We had a few ideas on how monitor generation should work, from flat, highly efficient monitors to high level ones that preserves the statechart’s hierarchy in the code itself (creating easily extendable and readable source files in the process). We also had a few options somewhere between the two extremities, but most systems either have a lot, or nearly no extra computing power that can be used for monitoring, so a midways approach isn’t really necessary. We ended up implementing most of the functionality for both the high and the low level monitor generators. So, let’s dive into how they work!
High level monitor generation
This method preserves the hierarchy of the statecharts completely. As a specification might consist of multiple statecharts, a statechart handler is responsible for the top level functionality. It works with a signal handler that connects the world to the environment – which handles the signal queues. Signal queues are one of the parts that has to be written by hand. It will mostly operate by either using shared memory (locking functions are built in) for the queues, or by attaching to a network interface to monitor packets, where certain packets raise certain signals. The statechart handler is responsible for the proper working of statecharts, which in turn contain states and transitions. These are all separate classes derived from a generic state and transition class, which allows the developers to extend the functionality of certain actions or guards. Names for states are also stored as strings which can be used to send informative error messages. For example, a state with a built in, and a custom entry action is represented as follows:
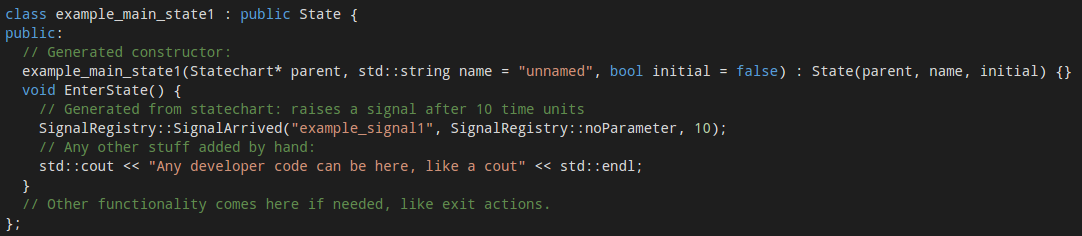
The handling of time is delegated to a separate class. This uses standard C++11 timing features and a clock with millisecond resolution by default, but can be easily changed to platform specific solutions: three functions need to be replaced in the class, one for getting the current time, one for getting the current time with an offset (which is needed for timers), and the comparison function between two timestamps.
This allows the generator not only to be used for monitor generation, but as a general tool to create object oriented C++ code from statecharts. This naturally results in a larger codebase than a low level monitor would, which is usually problematic when running on embedded systems.
Monitors with low overhead
After we realised that a BeagleBone PRU (which is what we wanted the monitor to run on) only has 8kB of code memory, a low level monitor generator had to be implemented. Code for handling hierarchy was the first to go – flat statecharts are just as good as hierarchical ones, when the memory limit is 8kB. The statechart names can also be omitted – even if it’s a less friendly method for the eye, storing an ID is enough to be to trace back which error state was reached. Creating child classes for states is also unacceptable overhead on such a small system, so we decided to use a general state class with function pointers. C++11 compilers are also seldom on embedded systems, so the code was downgraded to be C++98 compliant (which is the reason why no nice looking initialization lists are used). Then a single function running in an infinite loop checks for any changes in the signal que (in shared memory), and takes timesteps accordingly.
By now, you should have quite a bad feeling about how such code might look like. Well, wait no more, here is a small part from an example statechart, which shows how a transition is handled and the monitoring code is built:
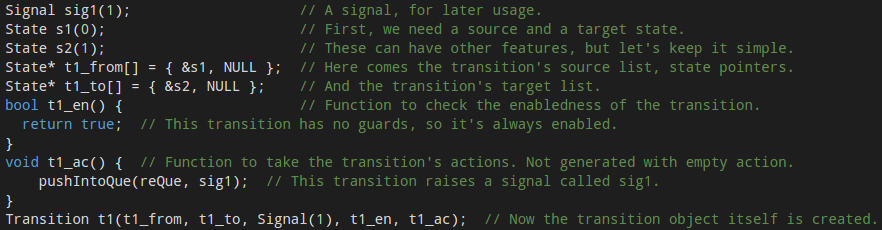
Looks horrible, right? Still: that’s how low level monitors for embedded systems are born.
Cyber-Physical Systems (CPS) are on one hand close to embedded systems as they are also built from sensors, controllers and actuators, where the sensors gather heterogeneous information from the environment, the controllers observe the gathered information and order the actuator to modify the environment according to the observed information. On the other hand, CPS systems are aiming to harvest the benefits of elastic cloud based resources to provide more sophisticated automation services.
As part of the MoDeS3 project we successfully integrated the safety logic that controls our model railways, with IBM Bluemix and Node-RED.
![]()
Bluemix is an open standards, cloud platform for building, running, and managing apps and services. Bluemix is designed to make developers’ lives easier. That’s why it provides developer teams of all sizes with the flexibility to scale compute power at a very granular level, seamlessly collaborate on source code and shared APIs, and manage apps’ performance, logs and costs from a single dashboard.
Bluemix has three open source compute options to power your applications:
Source of information: IBM Bluemix homepage
Node-RED is a tool for wiring together hardware devices, APIs and online services in new and interesting ways. It provides a browser-based flow editor that makes it easy to wire together flows using the wide range nodes in the palette. Flows can be then deployed to the runtime in a single-click.With over 225,000 modules in Node’s package repository, it is easy to extend the range of palette nodes to add new capabilities.
The light-weight runtime is built on Node.js, taking full advantage of its event-driven, non-blocking model. This makes it ideal to run at the edge of the network on low-cost hardware such as the Raspberry Pi as well as in the cloud.
Source of information: Node-RED homepage

As we describer earlier in a blogpost we designed the model railway control logic, also known as safety logic, with YAKINDU Statechart Tools. YAKINDU Statecharts enabled automatic code generation from the designed statecharts. This way we could directly create the implementation of the safety logic, based on statechart semantics.
However, generating codes automatically were not enough. We had to integrate custom Java codes to the generated codes through an interface. In this way we could connect the statecharts with the physical model railway track, including the BeagleBone Black based embedded controllers.
After that as an experiment we designed the communication module, originally implemented in Java and that is neccessary for communication between the statecharts, in Node-RED. The high-level signals used in the communication have been constructed as flows in Node-RED, depicted on the following figure.

As you can see, although different requests, originating from the left-hand side, has different flows containing some functions, they all end in the same response node. It was in order to make the design easier and less redundant, excluding the status and error logging nodes used for debug purposes.
So, as you may have already guessed the Node-RED flows and the generated statechart codes have been deployed into IBM Bluemix. Each turnout has its own statechart and they run separately, connected through the Node-RED flow, to make the communication easier and use cutting-edge Internet of Things technolgy!

We deployed each component (statecharts that control the turnouts and their nearby sections, and the communication module designed in Node-RED) into the IBM Bluemix as a container. Six containers were running the generated Java codes, each in its own, and the seventh container was deploying the Node-RED flow. They were put in the same subnetwork, so all the statecharts could communicate with the Node-RED flow as described above.

On a local machine working at the Fault Tolerant Systems Research Group at BME, only a proxy module was running that received signals from the YAKINDU statecharts to stop the trains if neccessary. This module periodically transmitted status about the track to the cloud, so the statecharts could make decisions based on the real-world sensor information.
Although deploying a safety-critical system into the cloud is strongly opposed, due to network latencies, nondeterministic instabilities of the cloud, noisy neighbours in the virtual machines running in the cloud, etc, it was an interesting experimentation. It was fascinating to see that the section in danger, where the trains could collide, was disabled from the cloud. Despite we did not know where the containers were running exactly in the cloud (e.g. in the EU/USA/Asia), the network latency was low enough not to have serious implications in our case.
We were more than satisfied with the avilability and the stability of IBM Bluemix, so we strongly recommend to give it a try. It has a strong community which is eager to help you if you have any difficulties with the cloud services offer by IBM.
Last but not least, we would like to recommend Node-RED as well. If you are either a Java Script developer, or you would like to connect your embedded systems together, you may find it really useful.
Delivered in cooperation with Daniel.

Hi everyone! Let me start by introducing our project called MoDeS3, which stands for Model-based Demonstrator for Smart and Safe Systems. The main goal of our IoT challenge application is to demonstrate the many cool and innovative ways in which open source modeling tools can be used for systems development in the age of Internet-of-Things.
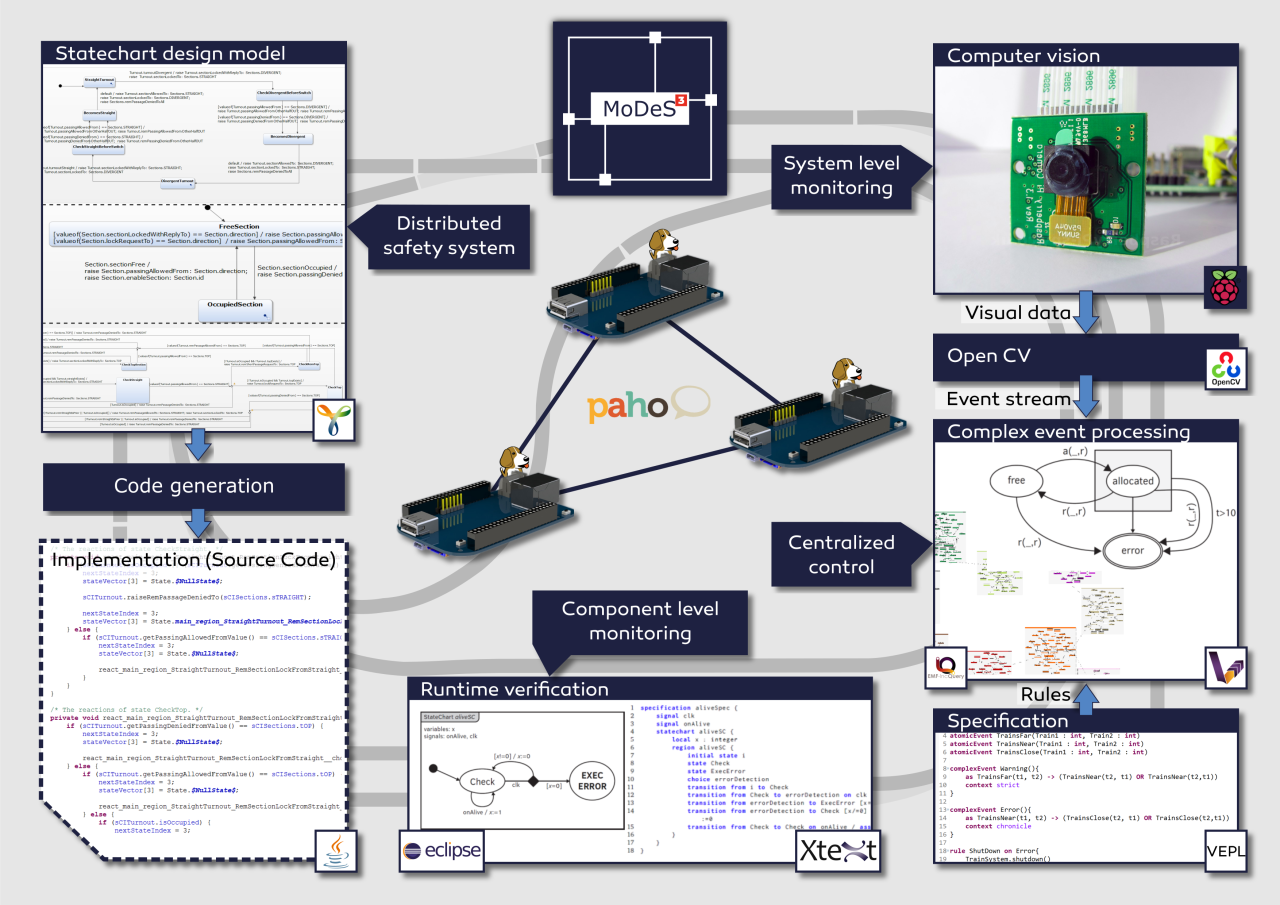
Our case study is a railway system: users can control trains arbitrarily as long as it is not dangerous. Accidents and dangerous situations are detected using sensors embedded into the track: they sense the trespass of the trains and send this information to the controllers. It is important to note that this is just local information, so we have to ensure that it will be shared between the components. We employ six BeagleBone Black (BBB) embedded computers to run the safety logic, configured as a distributed system, where each BBB is responsible for some track sections.
As you can imagine, the real software engineering challenge is how to develop the distributed safety logic. We use the open source Yakindu Statecharts tool to design the software components. It is much easier than manual programming, as it provides a code generator to produce C or Java code.
In order to supercharge the expressive power of Yakindu models, we have developed custom validation and verification rules. For this purpose, we used the open source EMF-IncQuery engine. Our IncQueries can be used to analyse the well-formedness of the models, for example to check if the state chart is deterministic and complete. This turned-out to be a useful feature as many design time errors were found, well before deployment and debugging even began!
In addition to the validators, we have also developed model transformations to generate formal models from the state chart models. These formal models, together with associated model checking tools such as UPPAAL, are used to check the deadlock freedom and reachability of the states in the model. In the future, we plan to work more in this direction, in order to automatically analyse other properties such as fault-tolerance properties. We developed the model transformations using the VIATRA framework.
To make distributed systems work in practice, we need communication channels. For this project, we are going to use MQTT for its simplicity, reliability and flexibility. The open source Eclipse Paho framework helps us in establishing and maintaining the communication between the components.
In order to provide system-wide safety guarantees, we plan to build an additional layer on top of reliable communication channels, to facilitate runtime monitors. These smart components will evaluate the behaviour of the local components, and run locally on the PRU 32-bit microcontrollers of the BBBs. They will analyse if the communication works correctly and there is no problem within the controller itself.
To augment local monitors, the overall system status will be monitored using computer vision techniques. For this purpose, we attached a camera to a stage above the tracks that will observe the movement of the trains. The video stream is processed by OpenCV, a state-of-the-art open source computer vision library. We have implemented train recognition algorithms to detect the position of the trains.
The combination of local monitoring data and computer vision data will be aggregated on the system level and processed using complex event processing (CEP). The role of this high-level monitoring technique is to integrate multiple monitoring data sources and make sure that if the distributed safety logic does not work correctly, this additional level of logic can still bring the system to a safe state. Our system-level safety framework will be built using an open source complex event processing engine called VIATRA-CEP.